Building a Manga Translation Tool to Tackle My Backlog
And as a Refresher on Python
Date:- thoughts
If you’ve ever stared at a folder full of untranslated manga—or any other image with Japanese text—and felt overwhelmed, you’re not alone. While commissioning professional translations or learning Japanese is ideal, it’s impractical for a backlog as large as mine.
The Tech
I decided that to tackle the ever-growing backlog, I needed a DIY solution to read these stories now, even if the translations weren’t perfect. After some research and seeing the current landscape of options, the choice was made for a tech stack:
- Manga OCR
- Specialized for Japanese manga text, though it struggles with blurry or stylized fonts.
- PyQt6
- Chosen for its robust GUI widgets, ample variety of documentation and resources, and simple compatibility between its image objects and the ones used by Manga OCR and the Pillow image library.
- Google Translate
- Quick and accessible, even if translations occasionally miss nuance.
The next part was refreshing my Python knowledge. My Python skills were a bit rusty, but the good news is that it’s 2025, and we can skip the steps of searching for code snippets that showcase a feature. Instead, we can directly ask an AI to explain it to us, saving precious search time 😌. 1
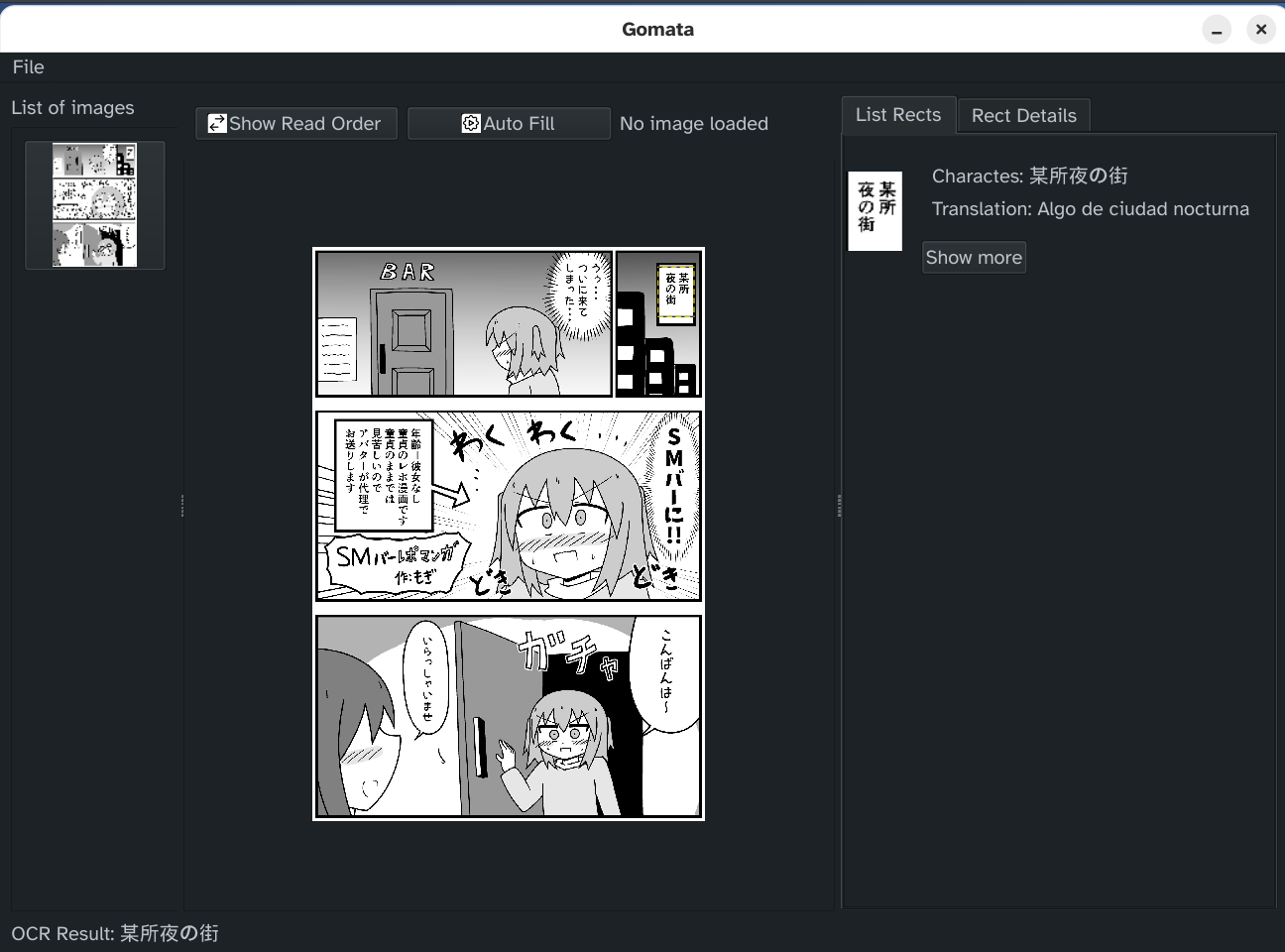
Building the Software
One of the main focuses was to keep it simple, so the process was more streamlined:
- Load an image or folder: Point the app to your manga files.
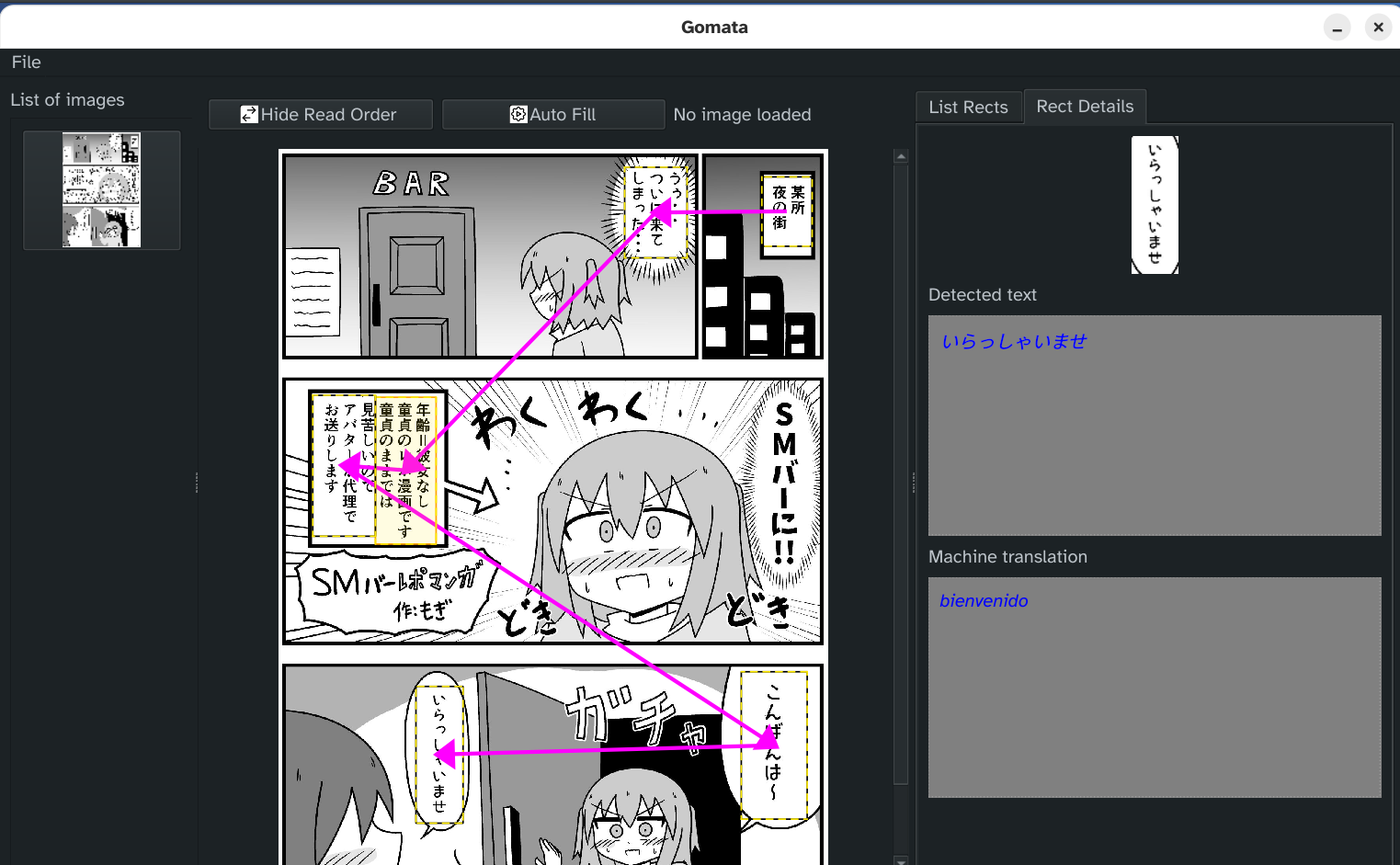
- Select text regions: Draw boxes around Japanese text bubbles.
- Extract and translate: Let Manga OCR (a Japanese-focused OCR tool) grab the text, then pass it to Google Translate.
- Save for later: Translations can be stored for reference or future tweaking. 2
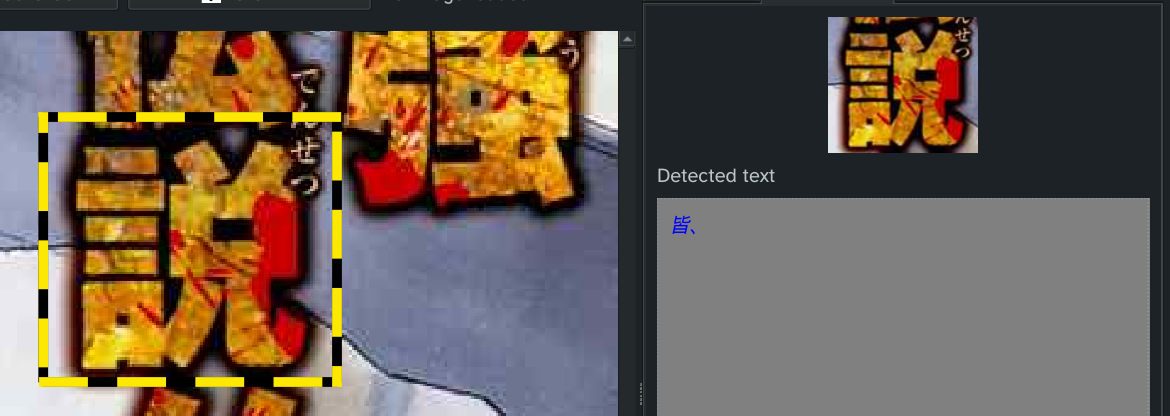
Limitations
This is a side project after all, and it has some limitations regarding the tech:
- Language-specific
- Manga OCR is optimized for Japanese, not Western languages.
- Image quality matters
- Blurry or overly stylized text can trip up the OCR.
- Translation accuracy
- Google Translate works, but context-heavy dialogue may confuse it.
Next Steps
- Add basic image editing tools to clean up text regions before OCR.
- Experiment with LLMs to improve translation quality.
Try It Yourself
The code is available on my GitHub.
You’ll need Python and uv to run it. Remember, it’s a work in progress.